
Community, Musings
My friend Git: Applying software version control principles and tools to creative writing

Jul
By Jeremy Hanson-Finger, author of Death and the Intern
One problem I’ve struggled with as a writer is keeping track of the changes I make to my work during the editorial process.
Organizing the versions of the text that correspond to each step in the production schedule is easy enough. You send your editor your manuscript. Your editor sends you substantive edits; you make them and send them back. Your editor sends you line edits; you make them and send them back. The same for copyedits and proofs. If you’ve done it all digitally you should have nine discrete files.
But the problem is, how do you keep track of changes you’re making to your text within a step in the process? The substantive editing phase is probably the worst for that, because that’s when you try out different ways of addressing major problems, which can involve moving around large pieces of text and introducing elements that could cause conflicts all over the manuscript.
In the past I’ve tried saving new copies by the seat of my pants and ended up with a folder of files with confusing names, significant difficulty remembering which contained which changes, and a lot of anxiety about things not being in their right place.
I’ve also ruthlessly deleted as I went, so that I only ever had one version of the document, which was less anxiety-inducing on one level, but it also gave me the feeling that I was missing out on the possibility of going back to salvage elements of past experiments.
The answer I eventually turned to came from looking to the world of software development.
Learning from software development
Software developers work with text. That text might be written in the programming language Ruby, or in Python (or some other kind of gem, or some other kind of snake), but ultimately, developers spend their days typing, deleting, and rearranging words and symbols in a text editor, just like fiction writers. That means that they encounter some of the same problems: they need to try out different ways of approaching issues while still being able to access any revision at any time, because inevitably some of the things they try aren’t going to work.
I work on the documentation team at the e-commerce company Shopify. The documentation team is responsible for the Help Center, a set of instructions for store owners using Shopify’s software. The documentation team follows a similar workflow to the developers at the company, using software called Git to handle version control of text files—in this case, primarily for instructional content rather than source code.
Version control with Git is based on a tree metaphor. You have a central branch (which you can think of as the trunk of the tree) called `master`. In the case of the Help Center, the content of `master` determines what visitors see when they access https://help.shopify.com.
When team members want to make changes, they copy `master` from the online source code repository to their own computer, create a new “branch”, make changes, and “commit” their changes to that branch with a short message explaining them. The act of “committing” creates what is called a “commit” in Git speak. A commit is like a saved game in a video game—a snapshot of the entire project at that point in time.
This is a set of commits from an open source software project:
- Replace `assert_equal nil,` with a `assert_nil`
- Limit how many blocks can be nested during parsing
- Use a loop to strictly parse binary comparisons to avoid recursion
Generally, developers try to make commits that change only one discrete element at a time. Best practice is also to tag them with messages phrased as present-tense instructions, as in the example above.
This strategy makes it easier to see at a glance what has changed and to undo a change if it causes problems.
After committing their changes, developers push their branch to the remote repository and then request to merge that branch back into `master`, at which point the other team members can review the changes.
Git stores the history of every commit that has been made, so you can go back and look at the documents that make up the project as they existed at any point in time, with the changes labelled conveniently, and compare them to each other in the line-by-line “diff” view.
With Git, you can also have unlimited branches, each of which can include different commits, so you can try out all sort of experiments without losing information in your `master` branch.
Git and me
Because I was the only person working on the project (good luck convincing your editor to learn Git), I didn’t need a remote repository for collaborative purposes, but it provided a good way to back everything up and make it accessible across multiple computers, and an easy graphical interface for comparing changes.
Shopify uses GitHub as a remote source code repository, but there are other options, like Bitbucket, which I used for my novel.
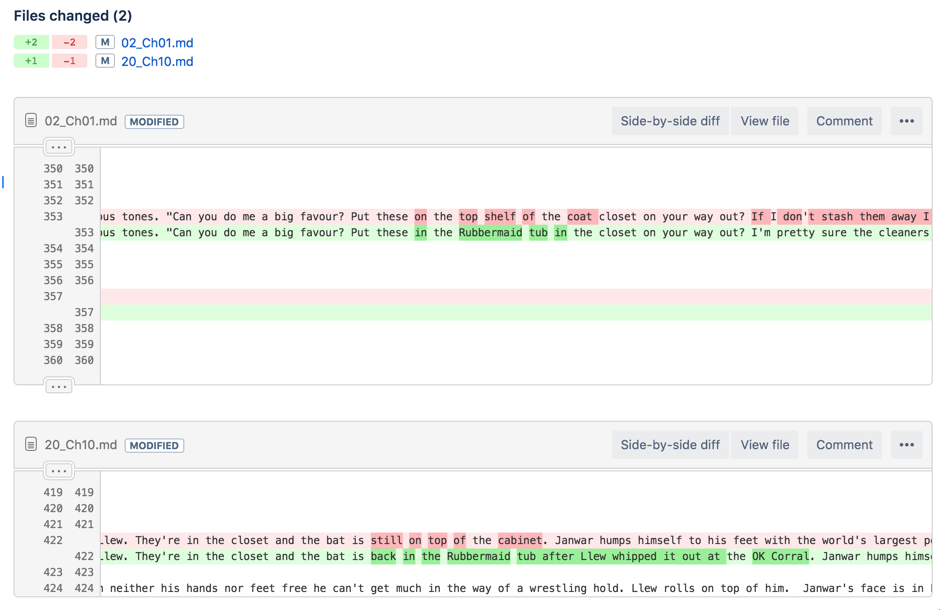
Here’s what the commit log for my novel looks like in Bitbucket:

And here’s what the diff view looks like in Bitbucket, comparing “Reference Llew’s bat in tub” with the previous commit. The text highlighted in red is the old version and the green is the new one:
Computer setup
In order to use this workflow, as well as installing and setting up Git, I had to save my project as plain text and use a text editor. I used Sublime Text, but there are tons of other options.
I chose to use Markdown format, which we also use at Shopify, because it’d allow me to represent italics (`_italic text_`) and headings (`# Level 1 heading`) and other simple formatting:

In order to commit changes and push branches to the remote repository, I used the command line interface (typing commands directly into the Terminal in OS X), because that was how I had learned, but there are also free graphical interfaces for Git like Sourcetree and GitX.
I didn’t have anyone else reviewing my requests to merge my branches into `master` (confusingly called “pull requests” in Git speak), but I stuck with that workflow because it provided another level of organization. For instance, these three commits, which are part of a larger change, are grouped together in one pull request:

At the end of the process, once I was ready to submit the next draft to my editor, I converted my markdown files to Word using Pandoc, which is a command-line tool that converts documents between different formats.
Thoughts on the experience
Using a Git-based workflow had so much of a beneficial psychological effect on me that it was definitely worth all of the setup time and maintenance, even if I didn’t make use of all of the features as much as I thought I might. Just knowing I could go back and easily access past changes, and that they’d all be organized, meant I could focus on the world of my book.
The most useful element of the Git workflow for me was treating changes as single-purpose commits. Breaking edits down into changes controlled enough that they could be described with short messages like “Reference Llew’s bat in tub” made me think about exactly what modifications I was making to the text and address any potential impact on other sections as I went.
That was a lot better than getting distracted as I went through the text line by line or skipping all over and fixing things on a whim. If I hadn’t taken this approach, I would have had far more continuity errors than I already did.
That said, Git was easy for me because I use it at work. Atlassian, the makers of Bitbucket, have great tutorials and documentation on Git, and there are plenty of online courses, but I think you have to already enjoy learning new computer skills to stick to the process.
If this sounds appealing to you, I’d highly recommend it—as well as having a really organized writing project and the associated sense of well-being, you’ll learn an interesting and marketable skill (Shopify isn’t the only company to use software version control for technical writing).
Other options
If learning new computer skills isn’t your jam, you might want to check out a tool like Draft, a web app that offers some of the same features in a more intuitive interface for writers. Draft refers to commits as, well, “drafts”, but it works about the same way.
And at the very least, if you use Word, try out Google Docs, because you don’t need to turn Track Changes on and it’ll keep a history of all your changes tucked away—-although you can only search by date if you’re trying to find something.
Neat, thanks for sharing, Jeremy! This makes me think the theory could be applied to other version control nightmares in the workplace. Might see if I can use for my next round of stakeholder consultations…